Paper Reading - Multi-Modal Classifiers for Open-Vocabulary Object Detection
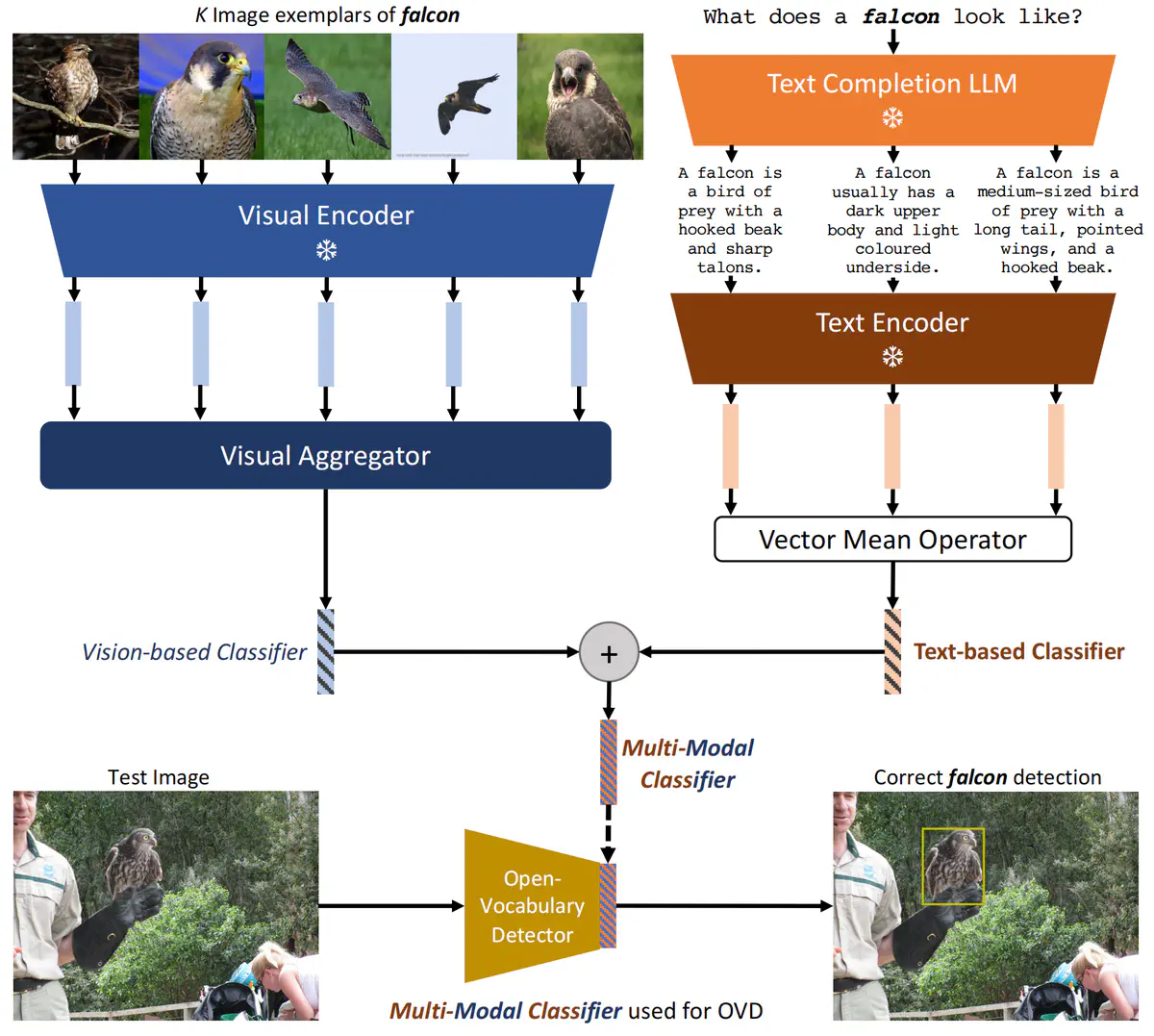 Image credit: Unsplash
Image credit: UnsplashHello!
Abstract
OVOD的目标是建立一个可以检测到不属于训练集类别的目标的模型,让用户可以指定一个感兴趣的新类别而不需要重新训练模型。
作者采用了一个标准的两阶段目标检测框架,采用三种方式来指定新的类别:
- 语言描述
- 图像示例
- 语言和图像相结合。
论文的主要贡献有三:
- 提出了一个LLM来生成目标类别的高质量语言描述,并建立了一个强大的文本分类器
- 采用了一个图像示例聚合器,可以接收任意数量的图像作为输入,构建视觉分类器
- 提出了一个简单的方法来融合语言描述和图像示例的信息,得到了一个多模态分类器
Introducrion
当前工作的主要缺陷有三:
生成的文本特征的判别能力完全依赖于预训练文本编码器,这样可能导致语义模糊。只是编码了类名不能区分两个概念。
- “nail"既可以指代“指尖的硬面”或“在木头上锤打的带平头的小金属钉,用于形成连接”
感兴趣目标的类别对用户来说可能是未知的,而示例图片却很容易被用户理解
- “dugong"是一种食草的海洋哺乳动物,有着可爱丰满的外表、海豚般的尾巴、圆圆的头和向下的鼻子
某些情况下,多模态信息更有利于指定感兴趣的类别
如一个具有独特翅膀花纹的蝴蝶
语言描述可能会过于冗长,且无法捕捉类别的所有复杂细节
而示例图片则可以包含“千言万语”, 成为文字的有效补充
作者提出一种多模态开放词汇对象检测器,通过自然语言描述、图像示例或两者相结合的方式来构建检测器上用于特定类别分类的分类器。
构建了一个通过向大语言模型提出问题,从而自动获取目标类别的视觉描述的方法,如:
- 问:“大麦町犬长什么样?” 答:“大麦町犬是一种典型的大型犬,被毛较短,白底黑斑。”
这种描述包含额外的视觉线索,可以增强文本编码器生成的分类器的判别能力
在某些情况下,收集类别合适的语言描述可能有些困难,或确定类之间的差异可能需要十分冗长且不必要的描述,如:
- 狗的品种“八哥”和“斗牛犬”具有相似的描述,这种相似的类别就可以通过图像示例(感兴趣类别的RGB图像)辅助来生成分类器
最后,作者提出了一种简单的方法来融合语言描述和图像示例,从而构建出多模态分类器。融合后的分类器性能优于任一单模态
重复创新点:
- 我们的自动方法可以获取丰富的自然语言描述,从而生成基于文本的分类器,优于以往完全依赖于类名的分类器
- 基于视觉的分类器可以通过视觉聚合器有效构建,通过指定图像示例来检索新类别
- 自然语言描述和图像示例可以简单结合成多模态分类器,优于任一单模态和现有方法。
Related Work
Closed-Vocabulary Object Detection
传统的目标检测(一阶段,两阶段)。这种目标检测中的分类器在训练集中进行学习,因而只有在训练集中的出现的目标才能在推理时被检测到,因此被称为封闭词汇物体检测。
Open-Vocabulary Object Detection**(OVOD)
OVOD 超越了封闭词汇的目标检测,使用户能够在推理时可以扩展或更改检测词汇,而无需重新训练模型。
我们的工作将 Detic 作为实验的起点,并研究了构建分类器的不同方法。
Low-shot Object Detection**
一些小样本目标检测工作在推理时会对新类别的图像示例进行编码,并用于检测新类别实例。
其他工作基于有限真值数据对新类别的检测器参数进行微调。而这与使用基于视觉的分类器进行开放词汇对象检测无关,因为在开放词汇对象检测中,没有新实例可供重新训练/微调。
Natural Language for Classification.
自然语言是分类语义信息的丰富来源。Pratt 等人在2022年提出的CuPL使用 GPT-3 模型提供详细的描述,以此改进了小样本图像分类。这项工作为我们使用来自 LLM 的自然语言描述信息提供了借鉴。
Methodology
Preliminaries
主要将类别分成了三类:
- C_TEST:预测阶段期望用户指定的新类别
- C_DET:归属于D_DET数据集,该数据集包含边界框坐标、类别标签和图像。
- C_IMG:归属于D_IMG数据集,该数据集仅包含图像及其类别标签。
一般情况下,C_TEST, C_DET和C_IMG之间可以重叠。
Architecture Overview
首先,选用常见的两阶段检测器CenterNet。与closed- vocabulary的目标检测中,将所有参数都在训练检测器时学习不同,OVOD中的分类器不是在训练过程中学习的,而是从其他来源(如预先训练好的文本编码器)单独生成的。因为分类器将参与分类推理阶段用户指定的新类。
Text-based Classifiers from Language Descriptions
现有的OVOD方法,如Detic和ViLD,仅采用简单的prompt来编码类名(a photo of a(n) {class name})。这种方法完全依赖于文本编码器对类名的理解来生成基于文本的分类器。
我们则利用了大语言模型(LLM)生成的类别语言描述,这可以得到额外的细节信息如视觉属性,进而增加分类器的判别能力。这也消除了具有双重含义的模糊类名的干扰,也同时节省人力,不需要人工手写描述。
具体来说,我们先给LLM提出一个问题:“What does a(n) {class name} look like?”,使用GPT-3的API为每个类别生成了10个描述并进行temperature采样,生成了格式为”{class name} is a …“的多种描述。我们用CLIP对文本进行编码,文本分类器由这些编码的均值得到。
在检测器训练阶段,感兴趣类(C_DET和C_IMG)的文本分类器是提前计算好的,需冻结其参数。除分类器之外,检测器的其他模块的参数则正常更新。在预测阶段,用于分类C_TEST的分类器也通过相似的方式计算。
分析:本文中的prompt比较单一,仅采用了一种提问方式,实际上可以选择多种提问方式,得到相同或相似的视觉描述。
同时,作者通过实验发现使用transformer架构来组合文本编码对OVOD任务来说并没有增益,甚至不如取平均的效果。
Vision-based Classifiers from Image Exemplars
对于某些类别,语言描述过长,或偶尔不知道类名时,可以使用图像示例。
对于c类的K张RGB图像,用CLIP视觉编码器编码得到K个特征。将这K个特征和一个可学习的CLS token一起输入到多层Transformer中。
Transformer用于在最好程度上聚合K个图像示例,CLS token的输出作为OVOD的视觉分类器。
训练Transformer采用 ImageNet-21k-P的示例,生成OVOD的视觉分类器时采用ImageNet-21k的示例
Offline Training(离线训练):视觉聚合器为离线训练(在训练检测器时不更新)。
思想:OVOD中,一个给定类别的分类器必须对其他类别具有判别性。为了得到这种具有判别能力的分类器,我们采用了对比学习。对于给定的类别,训练视觉聚合器的输出特征与其他类别输出特征的相似性最小,而与同一类别输出嵌入的相似性最大。因而采用InfoNCE loss函数。
数据:视觉聚合器应具有良好的通用性,而不是针对特定的下游 OVOD 词汇进行训练,因此使用 ImageNet-21k-P 数据集对其进行图像分类训练,该数据集包含 11K 个类别中的 11M张图像。
训练:在视觉聚合器训练过程中,对于类别 c,每个iter都会对两组不同的 K 个示例进行采样、增强,并由冻结的 CLIP 图像编码器进行编码。这两组样本分别输入视觉聚合器,从可学习的 [CLS] 标记中为类别 c 输出 2 个特征。对于一个batch size,InfoNCE loss可确保同一类别的样本具有相似的特征,而不同类别的样本则被区分开。训练完成后,视觉聚合器和视觉编码器将被冻结,并在检测器训练/测试期间为 C_DET ∪ C_IMG/C_TEST 中的类别提供视觉分类结果。
分析:使用图像示例进行开放词汇检测与小样本目标检测有一些相似之处。
但两者之间有一个关键的区别:小样本目标检测中,“新”类的标签在训练阶段可见。如,近期工作发现在小样本数据上对预先训练好的目标检测器进行微调能获得最佳结果。
而在开放词汇检测中,“新 “类没有边界框标签。我们使用图像示例(即不含边框的整体图像)来指定感兴趣的类别;而不会根据 “新"类的边框数据更新任何参数。
Constructing Classifiers via Multi-Modal Fusion
自然语言描述和图像示例之间可能存在互补信息
对于类c,文本分类器W_TEXT,视觉分类器W_IMG,多模态分类器W_MM如下融合:
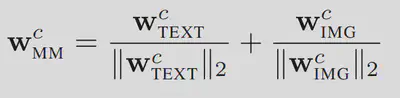
分析:我们通过实验发现,统一的多模态聚合器不适合用于生成OVOD的多模态分类器,因为它们会认为仅文本特征便足以解决对比学习任务,而完全忽略了视觉特征。
Boxuan Zhang
Master of Artificial Intelligence
My research interests include reliable machine learning(e.g., self-supervised & semi-supervised learning, learning and inference with Out-of-distribution data) and computer vision(e.g., classification and object detection).