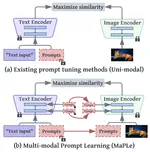
论文的主要贡献有三: 1. 第一个提出在 CLIP 中进行多模态prompt学习,以便更好地调整其视觉语言表征。 2. 为了将在文本和图像编码器中学习到的提示联系起来,提出了一种耦合函数,以明确地将视觉prompt作为其对应的语言prompt的条件。它充当了两种模态之间的桥梁,允许梯度相互传播,促进模态之间的协同。 3. 多模态prompt学习通过视觉和语言分支中的多个transformer块进行学习,以逐步学习两种模态的协同行为。这种深度prompt策略允许对上下文关系进行独立建模,从而为对齐视觉语言表征提供了更多的灵活性。